CFS调度器(5)-带宽控制#
Source: http://www.wowotech.net/process_management/451.html
前言#
什么是带宽控制?简而言之就是控制一个用户组在给定周期时间内可以消耗CPU的时间,如果在给定的周期内消耗CPU时间超额,就限制该用户组内任务调度,直到下一个周期。限制某个进程的最大CPU使用率是否真的有必要呢?如果一个系统中仅存在一个进程,限制该进程使用CPU使用率最大50%,当进程使用率达到50%的时候,就限制该进程运行,CPU进入idle状态。看起来好像没有任何意义。但是,有时候,这正是系统管理员可能想要做的事情。如果这些进程属于仅支付了一定CPU时间的客户或者需要提供严格资源的情况,则限制进程(或进程组)可能消耗的CPU时间的最大份额是很有必要的。毕竟付多少钱享受多少服务。本文章仅讨论SCHED_NORMAL进程的CPU带宽控制(CPU bandwidth control)。
注:代码分析基于Linux 4.18.0。
设计原理#
如果使用CPU bandwith control,需要配置CONFIG_FAIR_GROUP_SCHED和CONFIG_CFS_BANDWIDTH选项。该功能是限制一个组的最大使用CPU带宽。通过设置两个变量 quota 和 period,
period 是指一段周期时间,
quota 是指在 period 周期时间内,一个组可以使用的CPU时间限额。
当一个组的进程运行时间超过quota后,就会被限制运行,这个动作被称作 throttle。直到下一个 period 周期开始,这个组会被重新调度,这个过程称作 unthrottle。
在多核系统中,一个用户组使用 task_group 描述,用户组中包含CPU数量的调度实体,以及调度实体对应的 group cfs_rq 。如何限制一个用户组中的进程呢?我们可以简单的将用户组管理的调度实体从对应的就绪队列上删除即可,然后标记调度实体对应的 group cfs_rq 的标志位。quota 和 period的值存储在 cfs_bandwidth结构体中,该结构体嵌在tasak_group中,cfs_bandwidth结构体还包含runtime成员记录剩余限额时间。
每当用户组中的进程运行一段时间时,对应的 runtime 时间也在减少。系统会启动一个高精度定时器,周期时间是 period,在定时器时间到达后重置剩余限额时间 runtime 为 quota,开始下一个轮时间跟踪。
所有的用户组进程运行的时间累加在一起,保证总的运行时间小于 quota。每个用户组会管理CPU个数的就绪队列 group cfs_rq。每个 group cfs_rq 中也有限额时间,该限额时间是从全局用户组 quota 中申请。
例如,周期 period 值 100ms,限额 quota 值 50ms,2个CPU系统。CPU0 上 group cfs_rq首先从全局限额时间中申请5ms时间(此时runtime值为45),然后运行进程。当5ms时间消耗完时,继续从全局时间限额quota中申请5ms(此实runtime值为40)。CPU1上的情况也同样如此,先以就绪队列cfs_rq的身份从quota中申请一个时间片,然后供进程运行消耗。当全局quota剩余时间不足以满足CPU0或者CPU1申请时,就需要 throttle 对应的 cfs_rq。在定时器时间到达后,unthrottle 所有已经 throttle 的 cfs_rq。
总结一下就是,cfs_bandwidth 就像是一个全局时间池(时间池管理时间,类比内存池管理内存)。每个 group cfs_rq 如果想让其管理的红黑树上的调度实体调度,必须首先向全局时间池中申请固定的时间片,然后供其进程消耗。当时间片消耗完,继续从全局时间池中申请时间片。终有一刻,时间池中已经没有时间可供申请。此时就是throttle cfs_rq的大好时机。
数据结构#
每个task_group都包含cfs_bandwidth结构体,主要记录和管理时间池的时间信息。
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
ktime_t period; /* 1 */
u64 quota; /* 2 */
u64 runtime; /* 3 */
struct hrtimer period_timer; /* 4 */
struct list_head throttled_cfs_rq; /* 5 */
/* ... */
#endif
};
设定的定时器周期时间。
限额时间。
剩余可运行时间,在每次定时器回调函数中更新值为quota。
上面一直提到的高精度定时器。
所有被throttle的cfs_rq挂入此链表,在定时器的回调函数中便利链表执行unthrottle cfs_rq操作。
CFS 就绪队列使用cfs_rq结构体描述,和 bandwidth 相关成员如下:
struct cfs_rq {
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* 1 */
struct task_group *tg; /* 2 */
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled; /* 3 */
u64 runtime_expires;
s64 runtime_remaining; /* 4 */
u64 throttled_clock, throttled_clock_task; /* 5 */
u64 throttled_clock_task_time;
int throttled, throttle_count; /* 6 */
struct list_head throttled_list; /* 7 */
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
cfs_rq依附的cpu runqueue,每个CPU有且仅有一个rq运行队列。
cfs_rq所属的task_group。
该就绪队列是否已经开启带宽限制,默认带宽限制是关闭的,如果带宽限制使能,runtime_enabled的值为1。
cfs_rq从全局时间池申请的时间片剩余时间,当剩余时间小于等于0的时候,就需要重新申请时间片。
当cfs_rq被throttle的时候,方便统计被throttle的时间,需要记录throttle开始的时间。
throttled:如果cfs_rq被throttle后,throttled变量置1,unthrottle的时候,throttled变量置0;throttle_count:由于task_group支持嵌套,当parent task_group的cfs_rq被throttle的时候,其chaild task_group对应的cfs_rq的throttle_count成员计数增加。
被throttle的cfs_rq挂入
cfs_bandwidth->throttled_cfs_rq链表。
bandwidth贡献#
周期性调度中会调用update_curr()函数更新当前正在运行进程的虚拟时间。该进程bandwidth贡献也在此时累计。从进程依附的cfs_rq的可用时间中减去进程运行的时间,如果时间不够,就从全局时间池中申请一定时间片。在update_curr()函数中调用account_cfs_rq_runtime()函数统计cfs_rq剩余可运行时间。
static __always_inlinevoid account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec){ if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled) return; __account_cfs_rq_runtime(cfs_rq, delta_exec);}
如果使能CFS bandwidth control功能,cfs_bandwidth_used()返回1,cfs_rq->runtime_enabled值为1。__account_cfs_rq_runtime()函数如下:
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec){ /* dock delta_exec before expiring quota (as it could span periods) */ cfs_rq->runtime_remaining -= delta_exec; /* 1 */ expire_cfs_rq_runtime(cfs_rq); if (likely(cfs_rq->runtime_remaining > 0)) /* 2 */ return; /* * if we're unable to extend our runtime we resched so that the active * hierarchy can be throttled */ if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr)) /* 4 */ resched_curr(rq_of(cfs_rq)); /* 5 */}
进程已经运行delta_exec时间,因此cfs_rq剩余可运行时间减少。
如果cfs_rq剩余运行时间还有,那么没必要向全局时间池申请时间片。
如果cfs_rq可运行时间不足,assign_cfs_rq_runtime()负责从全局时间池中申请时间片。
如果全局时间片时间不够,就需要throttle当前cfs_rq。当然这里是设置TIF_NEED_RESCHED flag。在后面throttle。
assign_cfs_rq_runtime()函数如下:
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq){ struct task_group *tg = cfs_rq->tg; struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg); u64 amount = 0, min_amount, expires; int expires_seq; /* note: this is a positive sum as runtime_remaining <= 0 */ min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining; /* 1 */ raw_spin_lock(&cfs_b->lock); if (cfs_b->quota == RUNTIME_INF) /* 2 */ amount = min_amount; else { start_cfs_bandwidth(cfs_b); /* 3 */ if (cfs_b->runtime > 0) { amount = min(cfs_b->runtime, min_amount); cfs_b->runtime -= amount; /* 4 */ cfs_b->idle = 0; } } expires_seq = cfs_b->expires_seq; expires = cfs_b->runtime_expires; raw_spin_unlock(&cfs_b->lock); cfs_rq->runtime_remaining += amount; /* 5 */ /* * we may have advanced our local expiration to account for allowed * spread between our sched_clock and the one on which runtime was * issued. */ if (cfs_rq->expires_seq != expires_seq) { cfs_rq->expires_seq = expires_seq; cfs_rq->runtime_expires = expires; } return cfs_rq->runtime_remaining > 0; /* 6 */}
从全局时间池申请的时间片默认是5ms。
如果该cfs_rq不限制带宽,那么quota的值为RUNTIME_INF,既然不限制带宽,自然时间池的时间是取之不尽用之不竭的,所以申请时间片一定成功。
确保定时器是打开的,如果关闭状态,就打开定时器。该定时器会在定时时间到达后,重置全局时间池可用剩余时间。
申请时间片成功,全局时间池剩余可用时间更新。
cfs_rq剩余可用时间增加。
如果cfs_rq向全局时间池申请不到时间片,那么该函数返回0,否则返回1,代表申请时间片成功,不需要throttle。
如何throttle cfs_rq#
假设上述assign_cfs_rq_runtime()函数返回0,意味着申请时间失败。cfs_rq需要被throttle。函数返回后,会设置TIF_NEED_RESCHED flag,意味着调度即将开始。调度器核心层通过pick_next_task()函数挑选出下一个应该运行的进程。CFS调度器的pick_next_task接口函数是pick_next_task_fair()。CFS调度器挑选进程前会先put_prev_task()。在该函数中会调用接口函数put_prev_task_fair(),函数如下:
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}
prev指向即将被调度出去的进程,我们会在put_prev_entity()函数中调用check_cfs_rq_runtime()检查cfs_rq->runtime_remaining的值是否小于0,如果小于0就需要被throttle。
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
if (!cfs_bandwidth_used())
return false;
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0)) /* 1 */
return false;
if (cfs_rq_throttled(cfs_rq)) /* 2 */
return true;
throttle_cfs_rq(cfs_rq); /* 3 */
return true;
}
检查cfs_rq是否满足被throttle的条件,可用运行时间小于0。
如果该cfs_rq已经被throttle,这不需要重复操作。
throttle_cfs_rq()函数是真正throttle的操作,throttle核心函数。
throttle_cfs_rq()函数如下:
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, dequeue = 1;
bool empty;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))]; /* 1 */
/* freeze hierarchy runnable averages while throttled */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq); /* 2 */
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* throttled entity or throttle-on-deactivate */
if (!se->on_rq)
break;
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP); /* 3 */
qcfs_rq->h_nr_running -= task_delta;
if (qcfs_rq->load.weight) /* 4 */
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta);
cfs_rq->throttled = 1; /* 5 */
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
empty = list_empty(&cfs_b->throttled_cfs_rq);
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq); /* 6 */
if (empty)
start_cfs_bandwidth(cfs_b);
raw_spin_unlock(&cfs_b->lock);
}
throttle对应的cfs_rq可以将对应的group se从其就绪队列的红黑树上删除,这样在pick_next_task的时候,顺着根cfs_rq的红黑树往下便利,就不会找到已经throttle的se,也就是没有机会运行。
task_group可以父子关系嵌套。walk_tg_tree_from()函数功能是顺着cfs_rq->tg往下便利每一个child task_group,并且对每个task_group调用tg_throttle_down()函数。tg_throttle_down()负责增加cfs_rq->throttle_count计数。从依附的cfs_rq的红黑树上删除。
如果qcfs_rq运行的进程只有即将被dequeue的se一个的话,那么parent se也需要dequeue。如果
qcfs_rq->load.weight不为0,说明qcfs_rq就绪队列上运行的进程不止se一个,那么parent se理所应当不能被dequeue。设置throttle标志位。
记录throttle时刻。
被throttle的cfs_rq加入cfs_b链表中,方便后续unthrottle操作可以找到这些已经被throttle的cfs_rq。
tg_throttle_down()函数如下,主要是cfs_rq->throttle_count计数递增:
static int tg_throttle_down(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
/* group is entering throttled state, stop time */
if (!cfs_rq->throttle_count)
cfs_rq->throttled_clock_task = rq_clock_task(rq);
cfs_rq->throttle_count++;
return 0;
}
throttle cfs_rq时,数据结构示意图如下:
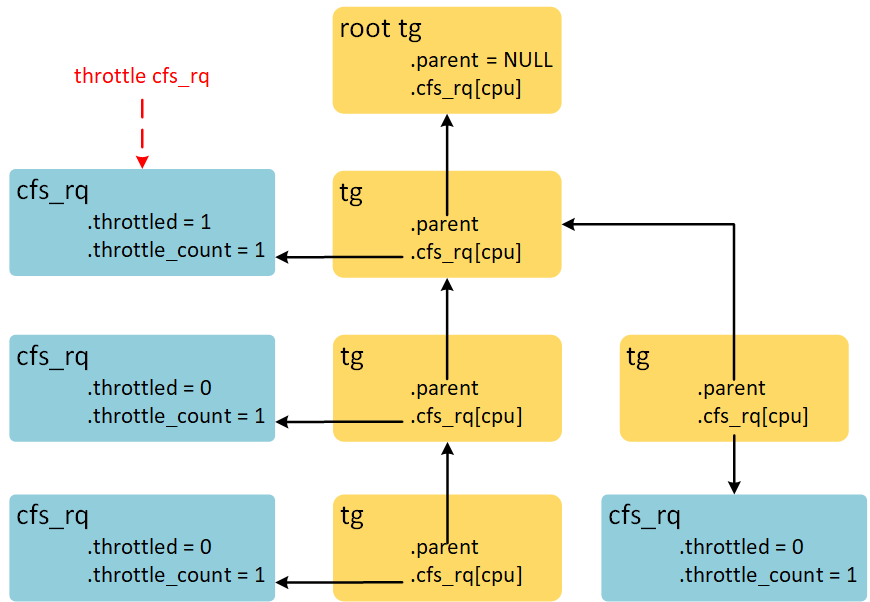
顺着被throttle cfs_rq依附的task_group的children链表,找到所有的task_group,并增加对应CPU的cfs_rq->throttle_count成员。
如何 unthrottle cfs_rq#
unthrottle cfs_rq 操作会在周期定时器定时时间到达之际进行。负责unthrottle cfs_rq操作的函数是unthrottle_cfs_rq(),该函数和 throttle_cfs_rq() 的操作相反。函数如下:
void unthrottle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
int enqueue = 1;
long task_delta;
se = cfs_rq->tg->se[cpu_of(rq)]; /* 1 */
cfs_rq->throttled = 0; /* 2 */
update_rq_clock(rq);
raw_spin_lock(&cfs_b->lock);
cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock; /* 3 */
list_del_rcu(&cfs_rq->throttled_list); /* 4 */
raw_spin_unlock(&cfs_b->lock);
/* update hierarchical throttle state */
walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq); /* 5 */
if (!cfs_rq->load.weight) /* 6 */
return;
task_delta = cfs_rq->h_nr_running;
for_each_sched_entity(se) {
if (se->on_rq)
enqueue = 0;
cfs_rq = cfs_rq_of(se);
if (enqueue)
enqueue_entity(cfs_rq, se, ENQUEUE_WAKEUP); /* 7 */
cfs_rq->h_nr_running += task_delta;
if (cfs_rq_throttled(cfs_rq))
break;
}
if (!se)
add_nr_running(rq, task_delta);
/* Determine whether we need to wake up potentially idle CPU: */
if (rq->curr == rq->idle && rq->cfs.nr_running)
resched_curr(rq);
}
unthrottle操作的做cfs_rq对应的调度实体,调度实体在parent cfs_rq上才有机会运行。
throttled标志位清零。
throttled_time 记录 cfs_rq 被 throttle 的总时间,throttled_clock在throttle_cfs_rq()函数中记录开始throttle时刻。
从链表上删除自己。
tg_unthrottle_up() 函数是 tg_throttle_down() 函数的反操作,递减
cfs_rq->throttle_count计数。如果unthrottle的cfs_rq上没有进程,那么无需进行enqueue操作。
cfs_rq->load.weight为0就代表就绪队列上没有可运行的进程。将调度实体入队,这里的for循环操作和throttle_cfs_rq()函数的dequeue操作对应。
tg_unthrottle_up()函数如下:
static int tg_unthrottle_up(struct task_group *tg, void *data)
{
struct rq *rq = data;
struct cfs_rq *cfs_rq = tg->cfs_rq[cpu_of(rq)];
cfs_rq->throttle_count--;
if (!cfs_rq->throttle_count) {
/* adjust cfs_rq_clock_task() */
cfs_rq->throttled_clock_task_time += rq_clock_task(rq) -
cfs_rq->throttled_clock_task;
}
return 0;
}
除了递减cfs_rq->throttle_count计数外,还计算了throttled_clock_task_time时间。和throttled_time不同的是,throttled_clock_task_time时间还包括由于parent cfs_rq被throttle的时间。虽然自己是unthrottle状态,但是parent cfs_rq是throttle状态,自己也是没办法运行的。所以throttled_clock_task_time统计的是cfs_rq->throttle_count从非零变成0经历的时间总和。
周期更新 quota#
带宽的限制是以task_group为单位,每一个task_group内嵌cfs_bandwidth结构体。周期性的更新 quota 利用的是高精度定时器,周期是 period。struct hrtimer period_timer嵌在cfs_bandwidth结构体就是为了这个目的。定时器的初始化函数是init_cfs_bandwidth()。
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
raw_spin_lock_init(&cfs_b->lock);
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
INIT_LIST_HEAD(&cfs_b->throttled_cfs_rq);
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED);
cfs_b->period_timer.function = sched_cfs_period_timer;
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
}
初始化两个hrtimer,分别是period_timer和slack_timer。period_timer的回调函数是sched_cfs_period_timer()。回调函数中刷新quota,并调用distribute_cfs_runtime()函数unthrottle cfs_rq。distribute_cfs_runtime()函数如下:
static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b,
u64 remaining, u64 expires)
{
struct cfs_rq *cfs_rq;
u64 runtime;
u64 starting_runtime = remaining;
rcu_read_lock();
list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq, /* 1 */
throttled_list) {
struct rq *rq = rq_of(cfs_rq);
struct rq_flags rf;
rq_lock(rq, &rf);
if (!cfs_rq_throttled(cfs_rq))
goto next;
runtime = -cfs_rq->runtime_remaining + 1;
if (runtime > remaining)
runtime = remaining;
remaining -= runtime; /* 2 */
cfs_rq->runtime_remaining += runtime; /* 3 */
cfs_rq->runtime_expires = expires;
/* we check whether we're throttled above */
if (cfs_rq->runtime_remaining > 0)
unthrottle_cfs_rq(cfs_rq); /* 3 */
next:
rq_unlock(rq, &rf);
if (!remaining)
break;
}
rcu_read_unlock();
return starting_runtime - remaining;
}
循环便利所有已经throttle cfs_rq,函数参数remaining是全局时间池剩余可运行时间。
remaining是全局时间池剩余时间,这里借给cfs_rq的时间是runtime。
如果从全局时间池借到的时间保证cfs_rq->runtime_remaining的值应该大于0,执行unthrottle操作。
另外一个slack_timer的作用是什么呢?我们先思考另外一个问题,如果cfs_rq从全局时间池申请5ms时间片,该cfs_rq上只有一个进程,该进程运行0.5ms后就睡眠了,按照CFS的代码逻辑,整个cfs_rq对应的group se都会被dequeue。那么剩余的4.5ms是否应该归返给全局时间池呢?如果不归返,可能这个进程失眠很久,而其他CPU的cfs_rq很有可能申请不到5ms时间片(全局时间池时间剩余4ms)导致throttle,实际上可用时间是8.5ms。因此,我们针对这种情况会归返部分时间,可以用在其他CPU上消耗。这步处理的函数调用流程是dequeue_entity()->return_cfs_rq_runtime()->__return_cfs_rq_runtime()。
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq){ struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg); s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime; /* 1 */ if (slack_runtime <= 0) return; raw_spin_lock(&cfs_b->lock); if (cfs_b->quota != RUNTIME_INF && cfs_rq->runtime_expires == cfs_b->runtime_expires) { cfs_b->runtime += slack_runtime; /* 2 */ /* we are under rq->lock, defer unthrottling using a timer */ if (cfs_b->runtime > sched_cfs_bandwidth_slice() && !list_empty(&cfs_b->throttled_cfs_rq)) start_cfs_slack_bandwidth(cfs_b); /* 3 */ } raw_spin_unlock(&cfs_b->lock); /* even if it's not valid for return we don't want to try again */ cfs_rq->runtime_remaining -= slack_runtime; /* 4 */}
min_cfs_rq_runtime的值是1ms,我们选择至少保留min_cfs_rq_runtime时间给自己,剩下的时间归返全局时间池。全部归返的做法也是不明智的,有可能该cfs_rq上很快就会有进程运行。如果全部归返,进程运行的时候需要立刻去全局时间池申请,效率低。
归返全局时间池slack_runtime时间。
开启slack_timer定时器条件有2个(从注释可以得知,使用定时器的原因是当前持有rq->lock锁)。
全局时间池的时间大于5ms,这样才有可能供其他cfs_rq申请时间片(最小申请时间片大小是5ms)。
已经存在throttle的cfs_rq,现在开启slack_timer,在回调函数中尝试分配时间片,并unthrottle cfs_rq。
cfs_rq剩余可用时间减少。
slack_timer定时器的回调函数是sched_cfs_slack_timer()。sched_cfs_slack_timer()调用do_sched_cfs_slack_timer()处理主要逻辑。
static void do_sched_cfs_slack_timer(struct cfs_bandwidth *cfs_b){ u64 runtime = 0, slice = sched_cfs_bandwidth_slice(); u64 expires; /* confirm we're still not at a refresh boundary */ raw_spin_lock(&cfs_b->lock); if (runtime_refresh_within(cfs_b, min_bandwidth_expiration)) { /* 1 */ raw_spin_unlock(&cfs_b->lock); return; } if (cfs_b->quota != RUNTIME_INF && cfs_b->runtime > slice) /* 2 */ runtime = cfs_b->runtime; expires = cfs_b->runtime_expires; raw_spin_unlock(&cfs_b->lock); if (!runtime) return; runtime = distribute_cfs_runtime(cfs_b, runtime, expires); /* 3 */ raw_spin_lock(&cfs_b->lock); if (expires == cfs_b->runtime_expires) cfs_b->runtime -= min(runtime, cfs_b->runtime); raw_spin_unlock(&cfs_b->lock);}
检查period_timer定是时间是否即将到来,如果period_timer时间到了会刷新全局时间池。因此借助于period_timer即可unthrottle cfs_rq。如果,period_timer定是时间还有一段时间,那么此时此刻需要借助当前函数unthrottle cfs_rq。
全局时间池剩余可运行时间必须大于slice(默认5ms),因为cfs_rq申请时间片的单位是5ms。
distribute_cfs_runtime()函数已经分析过,根据传递的参数runtime计算可以unthrottle多少个cfs_rq,就unthrottle几个cfs_rq,尽力而为。
用户空间如何使用#
CFS bandwidth control提供的接口是以cgroupfs的形式呈现。提供以下三个文件。
cpu.cfs_quota_us: 一个周期内限额时间,就是文中一直说的quota
cpu.cfs_period_us: 一个周期时间,就是文中一直说的period
cpu.stat: 带宽限制状态信息
默认情况下cpu.cfs_quota_us=-1,cpu.cfs_period_us=100ms。quota的值为-1,代表不限制带宽。我们如果想限制带宽,可以往这两个文件写入合法值。quota和period合法值范围是1ms~1000ms。除此之外还需要考虑层级关系。写入cpu.cfs_quota_us负值将不限制带宽。
关于上文一直提到cfs_rq向全局时间池申请时间片固定大小默认是5ms,当然该值也是可以更改的。文件路径如下:
/proc/sys/kernel/sched_cfs_bandwidth_slice_us
cpu.stat文件会输出以下3点信息。
nr_periods: 目前已经经历时间周期数
nr_throttled: 用户组发生带宽限制次数
throttled_time: 用户组中调度实体总的限制时间和
用户组层级限制#
cpu.cfs_quota_us和cpu.cfs_period_us接口可以将一个task_group带宽控制在:max(c_i) <= C(这里C代表parent task_group带宽,c_i代表它的children taskgroup)。所有的children task_group中最大带宽不能超过parent task_group带宽。但是,允许所有的children task_group带宽总额大于parent task_group带宽。即:\Sum (c_i) >= C。所以,task_group被throttle有两种可能原因:
task_group在一个周期时间内消耗完自己的quota
parent task_group在一个周期时间内消耗完自己的quota
第2种情况下,虽然child task_group仍然剩余quota没有消耗,但是child task_group也必须等到parent task_group下个周期时间到来。
使用举例#
设置task_group带宽100%
period和quota都设置250ms,相当于提供task_group 1个CPU的带宽资源,总的CPU使用率是100%。
echo 250000 > cpu.cfs_quota_us /* quota = 250ms */echo 250000 > cpu.cfs_period_us /* period = 250ms */
设置task_group带宽200%(多核系统)
500ms period和1000ms quota设置相当于提供task_group 2个CPU的带宽资源,总的CPU使用率是200%。
echo 1000000 > cpu.cfs_quota_us /* quota = 1000ms */echo 500000 > cpu.cfs_period_us /* period = 500ms */更大的period时间,可以增加task_group吞吐量。
设置task_group带宽20%
以下配置可以使用20% CPU带宽资源。
echo 10000 > cpu.cfs_quota_us /* quota = 10ms */echo 50000 > cpu.cfs_period_us /* period = 50ms */
在使用更小的period的情况下,周期越短相应延迟越小。