调度点(Scheduler Point)#

图:内核调度点与协作#
{kind=link}
本文主要参考:[Linux Kernel Programming - A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization —— Kaiwan N Billimoria]
基本概念#
线程状态#

图:线程状态图(来自:https://idea.popcount.org/2012-12-11-linux-process-states/)
ON/OFF CPU#
🛈 注意,本小节是个题外话,不直接和本文相关,本文不涉及 Runnable 状态下 ON/OFF CPU 的分析,不喜可跳过。
光有线程状态其实对性能分析还是不足的。对于 Runnable 的线程,由于 CPU 资源不足排队、cgroup CPU limit 超限、等情况,可以再分为:
Runnable & ON-CPU - 即线程是可运行的,并且已经在 CPU 上运行。
Runnable & OFF-CPU - 线程是可运行的,但因各种资源不足或超限原因,暂时未在 CPU 上运行,排队中。
。 Brendan Gregg 的 [BPF Performance Tools] 一书中有这个图:
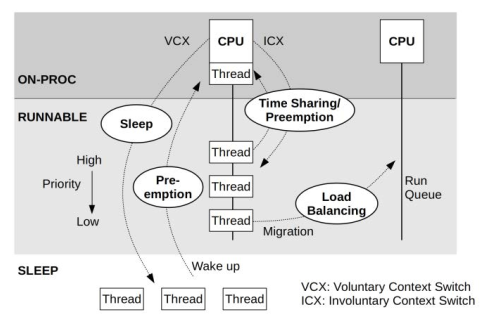
图:ON/OFF CPU 线程状态图(from [BPF Performance Tools] )
介绍几个术语:
voluntary switch: 线程自愿地离开 cpu(offcpu,即不运行),一般离开后,状态会变为 TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLEinvoluntary switch: 线程不自愿地离开 cpu(offcpu,即不运行),一般离开后,状态会还是 RUNNABLE 的。
理想世界#
日常生活中,如果我们说资源调度,你肯定会想到在一个组织中,有一个主管,去专职指挥资源调度。同样,在思考内核如何 调度线程 时,很自然地类比:
资源:空闲的CPU 资源
主管:一个独立的专用内核线程负责其它线程的调度
需要资源的项目:线程
让人惊讶的是,主管的类比不全对。内核并无专用线程负责其它线程的调度。[Linux Kernel Programming] 一书的 [The CPU Scheduler - Part 1] 是这样说的:
A subtle yet key misconception(误解) regarding how scheduling works is unfortunately held by many: we imagine that some kind of kernel thread (or some such entity) called the “scheduler” is present, that periodically runs and schedules tasks. This is just plain wrong;
in a monolithic OS such as Linux, scheduling is carried out by the
process contexts themselves, the regular threads that run on the CPU! In fact, the scheduling code is always run by the process context that is currently executing the code of the kernel, in other words, bycurrent. (调度过程是由 on-cpu 运行的当前线程在内核态执行的)This may also be an appropriate(合适的) time to remind you of what we shall call one of the golden rules of the Linux kernel:
scheduling code must never ever run in any kind of atomic or interrupt context. In other words,interrupt contextcode must be guaranteed to be non-blocking.
这里,可能会想,如果不是在独立管理线程中实现线程调度,那么,是不是用高频定时时钟中断来实现定时调度?
现实#
[Linux Kernel Programming] 一书的 [The CPU Scheduler - Part 1] 是这样说的:
Here’s a (seemingly) logical way to go about it: invoke the scheduler when the timer interrupt fires; that is, it gets a chance to run
CONFIG_HZtimes a second (which is often set to the value 250)! Hang on, though, we learned a golden rule inChapter 8, Kernel Memory Allocation for Module Authors – Part 1, in the Never sleep ininterrupt or atomic contextssection: you cannot invoke the scheduler in any kind ofatomic or interrupt context; thus invoking it within thetimer interruptcode path is certainly disqualified(不可接受的). So, what does the OS do? The way it’s actually done is that both thetimer interrupt context, and theprocess contextcode paths, are used to make scheduling work. We will briefly describe the details in the following section.(事实上,线程切换涉及timer interrupt context与process context两个状态下的程序协作来完成)
整个过程可以见下图:
图:内核调度点与协作#
图中信息量不少,不用担心。本文只关注红点部分。
如果你和我一样,在第一次看到上面的 finish_task_switch 和 try_to_wake_up 时一面茫然,那么没关系。在看过 [Linux Kernel Programming] 一书后,终于略懂一二。总结如下。
involuntary switch#
Process Runing ON CPU (正在CPU上运行的线程)在处理定时触发的timer interrupt soft IRQ TIMER_SOFTIRQ调用task_tick_fair()去计算Process Runing ON CPU是否应该被重新调度(即考虑抢占。即由于 CPU 资源不足有优先权更高的线程在等待排队、cgroup CPU limit 超限、等情况。如果线程需要被 off-cpu(抢占)那么会标记TIF_NEED_RESCHED位。完成中断处理,CPU 由
interrupt context变回process contextProcess Runing ON CPU在以下几个调度点可能触发真实的调度(即 off-cpu)Calling Blocking SYSCALL - 调用阻塞的系统调用,如 read/write
Exit from SYSCALL - 完成系统调用,返回用户态之前
after hardware interrupt handling - 处理硬件中断多后。
irq_exit()中。这包括上面步骤 2 结束后。
可见,大概可以分为标记需要切出 CPU、实际切出CPU两步。
voluntary switch#
与 involuntary switch 相近,但不包括其中的步骤 1 。
总结#
以上只是个大概的入门流程。如果想了解细节,建议直接阅读:[Linux Kernel Programming - A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization —— Kaiwan N Billimoria] 一书的 [The CPU Scheduler - Part 1] 。
如果你对用 eBPF/BPF 去观察线程切换,可能你会喜欢这个文章: